
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 애그리거트
- Pay
- Redis
- spring caching
- java17
- kakao
- IDDD
- zuul
- springcloud
- 반버논
- 값객체
- 바운디드컨텍스트
- spring-web
- MongoDB
- Conference
- spring6
- webframework
- ifkakao
- springboot
- docker
- Spring
- armeria
- Kotlin
- springboot3
- MSA
- mongo
- spring scheduler
- 개발자
- 신입
- ddd
- Today
- Total
Easy Understanding
(5) DDD와 아키텍처 - Layered, Hexagonal, CQRS, Event-Sourcing 본문

DDD의 가장 큰 장점 중 하나는 특정 아키텍처의 사용을 요구하지 않는다는 점이라고 한다.
하지만 책을 읽고 공부를 하다보면, 사실상 DDD에서 선택할 수 있는 괜찮은 아키텍처는 결국은 몇개 안 된다.
가장 간단한 것부터 순서대로 정리해 볼 것이다.
1. Layered Architecture
레이어드 아키텍처는 패턴계에서는 할아버지 같은 존재다.
이름 그대로 프로그램 내에서 계층을 나누는 설계 방식이다.
스프링의 예시가 가장 대표적이다.
Controller - Service - Domain - Repository
위와 같은 개발 방식은 레이어드 아키텍처의 대표적인 예시다.
의존의 방향성은 오로지 위에서 아래로만 내려간다.
public class UserController{
@Autowired
private UserService userService;
...
}
public class UserService{
@Autowired
private UserRepository userRepository;
...
}위와 같이 위에서 아래로만 의존성을 가지게 된다.
이렇게만 사용해도 일반적인 어플리케이션에서는 문제가 없는 패턴이다.
하지만 DDD의 관점에서 이 계층 구조는 다소 문제가 있다.
도메인이 순수하게 도메인 로직만 가지고 있지 않기 때문이다.
위의 계층 구조에서는 도메인이 데이터베이스 같은 인프라의 세부 구현을 알게 되어 버린다.
특히나 도메인 영역인 UserService 같은 클래스에서 인프라를 알게되는 것이다.
다음 예시의 경우 UserService는 직접적인 구현체인 UserRepository를 의존하게 된다.
public class UserRepository{
public void save(User user){
// DB에 대한 구현이 들어간다
}
...
}
public class UserService{
@Autowired
private UserRepository userRepository;
public void registerUser(User user){
userRepository.save(user);
}
...
}도메인 계층이 세부 구현을 알게되는 것 자체가 문제가 되므로
DDD에서는 이런 방식을 채용하려면 다른 방법이 있어야 한다.
다행히도 JPA를 사용하고 있으며 Repository Interface를 선언해서 사용하고 있다면,
어느정도 나쁘지 않은 방식으로 사용할 수 있는데
그것은 Repository Interface가 다음 등장할 아키텍처를 어느정도 준수하고 있기 때문이다.
2. Hexagonal Architecture
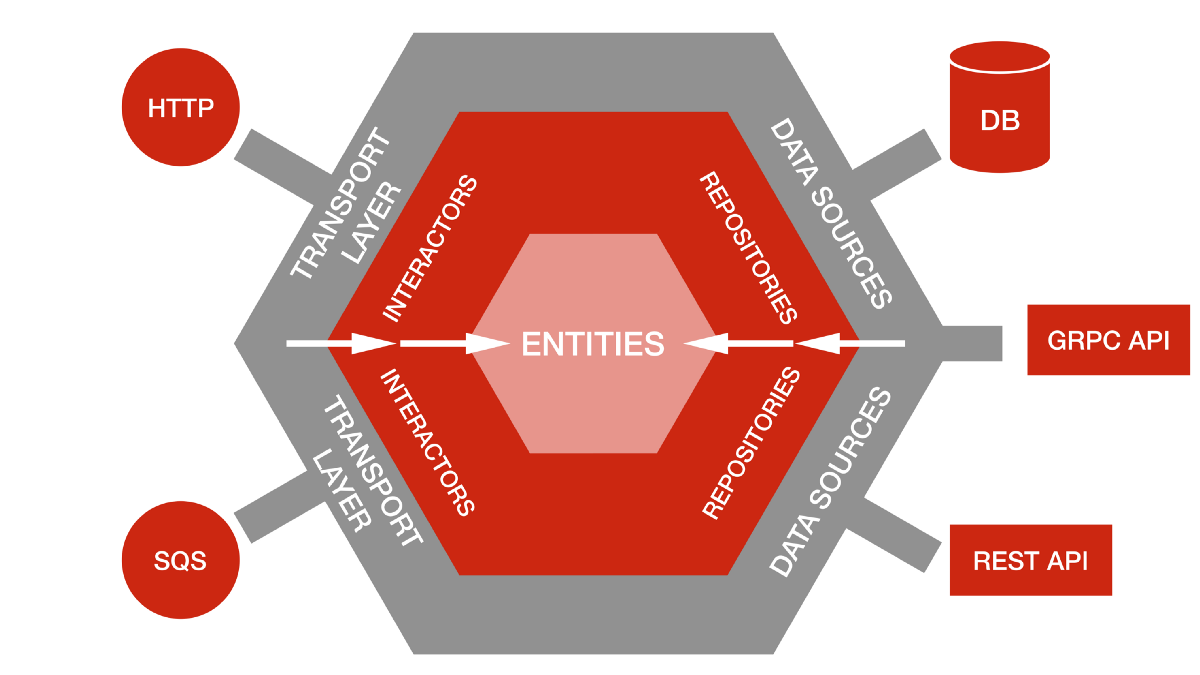
도대체 왜 육각형이 아키텍처 이름으로 나왔는지는 모르겠지만,
헥사고날 아키텍처는 위와 같이 육각형의 다이어그램으로 설명할 수 있다.
생긴 것은 레이어드 아키텍처와 굉장히 달라보이지만 사실 설계는 크게 바뀌는 것이 없다.
추가된 개념은 하나는 포트, 하나는 어댑터라고 부르는 두 컴포넌트다.
이전의 레이어드와는 다르게 Infra 영역이 가장 밖으로 나와있는 것을 확인할 수가 있다.
이전에 도메인 영역의 안쪽에 인프라 영역이 있던 것과 가장 큰 차이라고 볼 수 있다.
왼쪽의 두 요소인 HTTP, SQS는 각각 REST 요청을 받기위한 Controller와 Messaging Listener와 매칭된다.
오른쪽의 DB, RPC, Http Client 같은 것들은 모두 외부로 나가는 요청에 관련된 기술이다.
포트는 USB 구멍이고, 어댑터는 USB의 끄트머리 부분이라고 볼 수 있을까?
포트가 특정한 모양으로 생겼으면, 어댑터는 그 모양에 맞춰서 자신을 연결한다.
이걸로 살짝 예상해본다면
포트는 추상화된 인터페이스의 모습을 하고 있을 것이고,
어댑터는 구체화된 클래스의 모습을 하고 있지 않을까 생각해볼 수도 있지 않을까?
안으로 들어오는 Rest 요청의 경우,
Http 요청이 들어와서 컨트롤러에 할당되고, 내부에서 서비스를 주입받아 사용하게 된다.
그리고 그 서비스는 인터페이스로 구현되어 있다.
일반적인 스프링의 Controller 형태에 Service만 인터페이스로 구현되어 있는 모습이다.
public class ExampleController { // 이게 어댑터고
private ExampleService exampleService; // 이게 포트다(ExampleService는 인터페이스다)
@GetMapping("/example")
public ResponseEntity<String> example(){
...
exampleService.doExampleThing();
...
}
}
밖으로 나가는 DB 쿼리의 경우,
어플리케이션 서비스 같은 곳에서 인터페이스를 선언해두고,
어딘가 바깥 영역에 실제 구현체를 두면 된다.
이런 문제를 해결해주는 가장 좋은 방법 중 하나가 DI(Dependency Injection)다.
눈속임이라고 볼 수도 있겠지만 기존에 Infra에 의존하던 부분만 인터페이스로 바꿔만 주면 된다.
public interface UserRepository{ // 이게 포트이다.
public void save(User user);
...
}
public class UserService{
@Autowired
private UserRepository userRepository;
public void registerUser(User user){
userRepository.save(user);
}
...
}
@Repository
public class UserRepositoryMySQL(){ // 이게 어댑터다.
@Override
public void save(User user){
...
}
}위에 레이어드 아키텍처의 예시에서 구체적인 행위를 하는 클래스를 치우고 인터페이스를 두었다.
그리고 UserService는 그 인터페이스에 의존하게 된다.
그리고 추가적으로 다른 곳(infra 패키지 내부)에 UserRepository의 구현체만 생성해주면 된다.
이전에는 분명히 도메인 로직 안에 인프라 구현이 포함되었지만,
이제는 도메인은 인프라의 세부 구현은 모른다.
다만 스프링 프레임워크에서 알아서 의존성 주입을 해줄 것이다.
이로서 프레임워크와 DB 구현체는 그림처럼 가장 바깥에 존재하게 된다.
위에서도 이야기했지만 Spring JPA를 사용하면 헥사고날 아키텍처와 같이 인터페이스를 이용할 수 있다.
public interface UserRepository extends CrudRepository<User, Long> {}하지만 이 Repository가 CrudRepository라는 구체적인 인프라를 상속하고 있기 때문에
도메인에 인프라가 침투하는 문제가 발생한다.
내부적으로 도메인과 상관없는 메서드들이 무더기로 추가되기 때문.
이런 경우에는 다음과 같은 방법이 있기는 하다.
// 도메인 영역에 생성
public interface ExampleRepository {
public void save(Example e);
...
}
// 인프라 영역에 생성 1
public interface ExampleJpaRepository extends JpaRepository<Example, Long> {}
// 인프라 영역에 생성 2
@Repository
public class ExampleRepositoryImpl implement ExampleRepository {
@Autowired
private ExampleJpaRepository jpaRepository;
@Override
public void save(Example e){
this.jpaRepository.save(e);
}
...
}위처럼 도메인 영역에서는 인터페이스로 내가 필요한 도메인의 리파지토리를 작성한다.
그리고 인프라 영역에는 두 가지 리파지토리를 작성한다.
1. 해당 도메인에 대한 JpaRepository
2. 도메인 영역의 ExampleRepository에 대한 구현체. 내부에 jpaRepository를 주입받아 사용한다.
이렇게 하면 도메인 영역에서는 깔끔하게 도메인 리파지토리에 구현체를 주입받아서 사용할 수가 있게 된다.
헥사고날 아키텍처는 다른 방법론의 좋은 기반이 되기 때문에 저 그림을 확실히 이해하고 가는 것이 좋다.
항상 개발을 하다가 저 의존성의 방향이 맞는지 스스로 점검해 보는 것이 필요하다.
3. CQRS
참고로 이 개념들은 내용이 복잡해서 설명만으로는 제대로 이해가 되지 않을 수가 있다.
다음의 링크를 참고하면 더 이해하기 좋을 것이다. (https://www.popit.kr/cqrs-eventsourcing/)
나만 모르고 있던 CQRS & EventSourcing | Popit
CQRS는 네이밍에서 알 수 있듯이 명령과 쿼리의 역할을 구분 한다는 것이다. 즉 커맨드 ( Create – Insert, Update, Delete : 데이터를 변경) 와 쿼리 ( Select – Read : 데이터를 조회)의 책임을 분리한다는
www.popit.kr
우선 CQRS의 뜻을 보자면 Command Query Responsibility Segregation,
'명령과 조회의 책임을 분리'하는 것이다.
일반적으로 한 서버에서는 한 데이터베이스를 가지고 클라이언트의 요청을 처리한다.
그래서 하나의 DB에서 여러개의 요청을 처리하다보면,
DB의 부하를 처리하는 문제는 항상 발생하며 처리 난이도도 쉽지가 않다.
대략적으로 다음 같은 이슈가 있을 것이다.
1. Row의 업데이트를 할때 Lock
2. 클라이언트에서 필요한 데이터를 위해서 여러 애그리거트에 접근(잦은 조인)
이런 것들에 대해서 CQRS는 어느정도 해결책을 내려줄 수가 있다.
CQRS는 여러 방법이 있지만 가장 보편적인 방법은 서버를 나누는 것이다.
두 가지는 다음과 같은 역할을 한다.
- Command 전용 서버
오직 CUD(생성, 수정, 삭제) 요청만 처리하는 서버
Rest로 따지면 POST, PUT, DELETE만 처리하는 서버다.
여기에서는 엔터티에 getter를 사용하지 않는다.
사용가능한 쿼리와 관련된 메서드는 fromID 같은 메서드 하나뿐이다.
- Query 전용 서버
오직 R(읽기) 요청만 처리하는 서버
Rest로 따지면 GET만 처리하는 서버다.
실제 애그리거트와 모양이 같지 않고, 클라이언트에서 필요로 하는 테이블 스키마를 가진다.
각 테이블은 Join이 필요없는 정규화되지 않는 모양을 최대한 가져야 한다.
두 서버는 각자의 DB를 가지는 것이 좋다.
서로 같은 DB를 보게 되면 굳이 나눈 의미가 많이 줄어들기 때문이다.
그렇다면 데이터의 흐름은 어떻게 될까?
1. 일단 커맨드 서버에 클라이언트의 요청이 들어온다.
2. 커맨드 모델에서 이벤트를 발행하고, 본인의 DB에 데이터를 저장한다.
그리고 클라이언트는 커맨드의 종료 응답을 얻는다.(Command는 여기서 끝)
3. 커맨드에서 발행된 이벤트가 큐(메시지 큐든 뭐든지)에 쌓이게 된다.
4. 쿼리 모델에서는 큐에 쌓인 이벤트들을 가져와서 DB에 저장한다.
5. 클라이언트는 나중에 이 쿼리 서버에 요청을 날려서 데이터를 받아올 수 있다.
이렇게 하면 무조건 좋은지 아닌지는 사실 정확하게 말하기 어렵다.
그러므로 장단점을 고려해서 해당 아키텍처를 도입하는 것이 좋다.
장점
1. 데이터베이스의 지연 시간 대폭 감소 & 조회 안정성 증가
커맨드 서버에서는 사실상 클라이언트에게 데이터를 전달해주지 않을 뿐아니라,
데이터베이스나 서버에 문제가 생긴다하더라도, 클라이언트가 데이터를 얻는데 지장이 없다.
보통 대부분의 문제는 CUD에서 발생하기 때문에 안정적으로 서비스를 유지할 수 있게 된다.
2. DDD 애그리거트의 과도한 호출과 과도한 조인
DDD에서 도메인들을 열심히 쪼갤수록 결국 조인의 필요성은 많아질 것이다.
또한 클라이언트에서 필요한 데이터가 있다면, 많으면 수십개의 애그리거트의 리파지토리를 사용하게 될지도 모른다.
이런 어려움들은 쿼리 모델을 통해서 쉽게 해결된다.
3. 로직의 단순화
커맨드와 쿼리가 아예 서버가 나뉨으로서 코딩하는 방식은 더 일관화되고 직관적으로 될 수가 있다.
특히나 쿼리 모델은 애초에 클라이언트에게 제공하기 쉬운형태로 설계가 되기 때문에 더 구현이 쉬워질 수가 있다.
단점
1. 복잡성
그냥 복잡해진다. 여러 서버를 관리해야 하고, 카프카같은 메시징 플랫폼에도 익숙해져야 한다.
이벤트를 받는 쿼리 모델이 복잡해지면 그에 대해서 많은 고민이 들어갈 수 밖에 없다.
이런 것에 대한 고민은 다음 영상의 뒷부분에서 조금 다루고 있다.(https://www.youtube.com/watch?v=BnS6343GTkY&list=PLgXGHBqgT2TuFNlBkBRqf57__Z5IKfo8U&index=2)
2. 완전한 트랜잭션을 적용할 수가 없다.
CQRS는 기존에 사용하던대로 완벽하게 한 싸이클의 일관성을 유지하는 개념이 아니다.
CQRS에서는 결과적 일관성(Eventual Consistency)를 이용해 어떻게든 결과가 일치하는 방법을 이용한다.
3. 딜레이
쿼리모델은 커맨드모델에서 이벤트를 받아서 처리를 하므로, 실제로 처리된 내용과 딜레이가 있을 수가 있다.
딜레이는 제대로 개발되었을 경우에는 문제가 되지 않겠지만,
어떠한 문제에 의해서 심각하게 늦어질 경우에는 사용성에도 문제가 생기기 때문에 주의해야 한다.
(하지만 대부분의 경우 즉각적인 반응이 필요한 경우는 많지는 않다)
개인적으로 CQRS는 전문가의 노련한 경험이 있어야 성공할 수 있을 것 같다는 생각이 든다.
많은 삽질을 통해서 배워나가야 할 것 같은 아키텍처지만,
요새 점점 많은 곳들에서 이런 아키텍처를 성공적으로 도입해나가는 것 같아서 앞으로가 더 궁금해진다.
4. Event Sourcing
Event Sourcing은 위의 CQRS의 확장판이라고 볼 수 있다.
커맨드 모델에서 쿼리 모델로 보내는 '이벤트' 그 자체에 초점을 둔 개발 방식이다.
DDD에 에릭 에반스가 있다면,
Event Sourcing에는 그렉 영(greg young)이 있다.
자세한 내용은 몇 가지 발표 영상이 있어 링크를 남긴다.
https://www.youtube.com/watch?v=8JKjvY4etTY
https://www.youtube.com/watch?v=12EGxMB8SR8
위의 CQRS에서 달라 지는 점은 다음과 같다.
1. 이벤트는 일종의 로그의 형태를 가진다.
2. 이벤트는 커맨드 모델에서 이벤트 전용 DB에 저장된다.
3. 커맨드 서버에서는 주기적으로 이벤트를 이용해 애그리거트에 대한 스냅샷을 생성해서 보관한다.
4. 쿼리 모델에서는 이벤트들을 구독해서 본인의 모델에 저장한다.
커맨드 모델에서 애그리거트가 필요할 경우에는, 저장된 이벤트들을 Replay해서
모든 변경사항을 적용시킨 애그리거트를 사용하게 된다.
이벤트 소싱의 장점은 git 처럼 히스토리 자체를 저장하는 것이기 때문에,
히스토리가 중요한 도메인에 도움이 된다는 것이다.
아무래도 돈을 다루거나 감사와 관련된 업무라면 이런 것들이 도움이 될 때가 많을 것이다.
아직은 어려운 점이 더 많은 것이 이벤트 소싱이기도 하다.
아직까지 지식 체계가 부족하고 리스크가 많다.
노하우가 적기 때문에 그렇다.
아직은 좀 더 성숙하고 좋은 예시가 많이 나와야 할 것 같다.
'Study' 카테고리의 다른 글
| 웹 백엔드 관점으로 본 디자인 패턴 정리(1) - 디자인 패턴의 분류와 문법 (0) | 2022.05.05 |
|---|---|
| DDD를 적용한 간단한 결제 컨텍스트 개발해보기(with CQRS) (0) | 2022.04.03 |
| (4) DDD의 서비스/팩토리/패키지 - 코드를 작성하는 세부 방법들 (0) | 2022.03.02 |
| (3) DDD의 엔터티/값객체/애그리거트/리파지토리 - 코드에서 객체 정의하기 (1) | 2022.02.20 |
| (2) DDD의 도메인과 바운디드 컨텍스트 - 개발보다는 설계부터! (3) | 2022.02.12 |



